**本策略是对下面论文模型的一个简化复现和实验:**
Paper Reading | MoFE-Time: 时序预测的频域专家混合模型
论文链接:https://arxiv.org/pdf/2507.06502
*“时间序列预测作为重要的数据任务,在多个领域中发挥关键作用。随着大语言模型(LLMs)的发展,将LLMs作为时间序列建模的基础架构受到广泛关注。然而,现有模型在预训练-微调范式下难以同时建模时间与频率特征,导致复杂时间序列(需同时捕捉周期性和信号先验模式)的预测性能不足。本文提出MoFE-Time,一种结合时频域特征的专家混合(MoE)时间序列预测模型,通过预训练-微调范式迁移不同周期分布的先验模式知识。模型在注意力模块后引入时频单元(FTC)作为专家,利用MoE路由机制构建输入信号的多维稀疏表示。在6个公共基准上,MoFE-Time以MSE和MAE分别降低6.95%和6.02%的优势超越Time-MoE,成为新SOTA;在真实业务场景的专有数据集NEV-sales上的优异表现,验证了其商业应用有效性。”*
### 一、策略整体逻辑与运行流程
该策略是**基于MoFE-Time时序预测模型的A股中小综指微盘股量化交易策略**,核心目标是通过捕捉微盘股短期收益率的时频特征构建收益组合,同时在特定月份切换为ETF防御组合控制风险。整体流程分为「初始化-每日执行-调仓交易-风险控制」四大环节,具体如下:
#### 1. 初始化阶段(`initialize`)
完成策略基础配置与全局参数初始化,是策略运行的起点:
- **交易规则配置**:设置基准(中小综指399101.XSHE)、滑点(0)、手续费(万3)、真实价格等;
- **核心参数设置**:
- 调仓频率(每10天调仓1次)、持仓数量(10只);
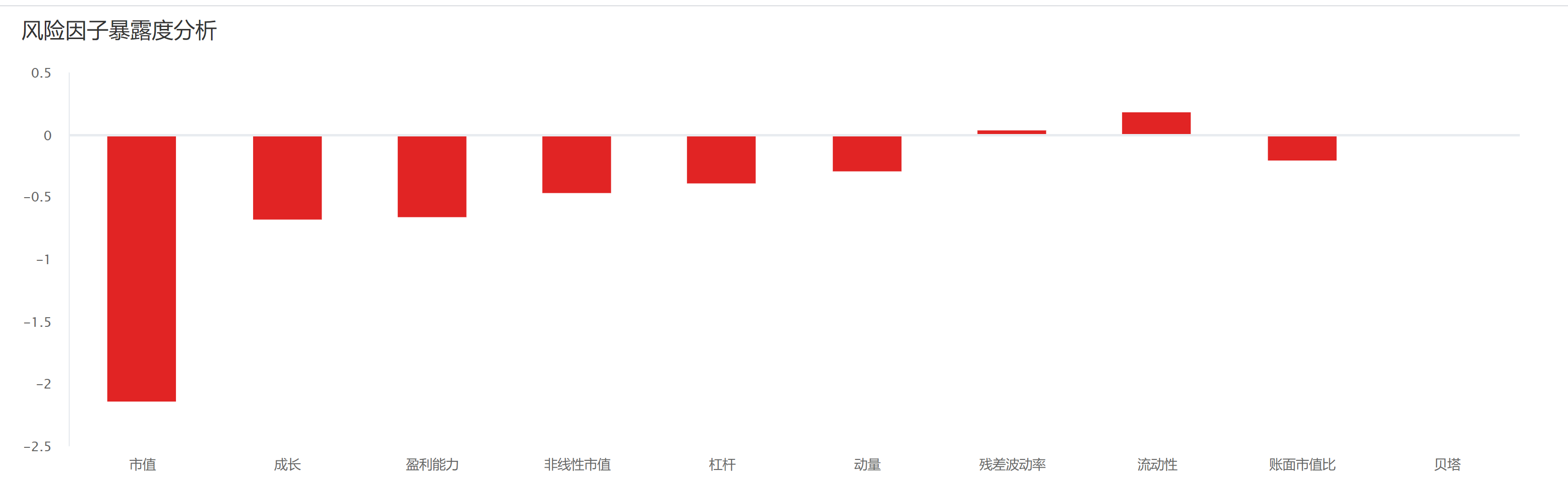
- MoFE-Time模型参数(序列长度20天、隐藏维度128、3层网络、4个专家、32个谐波分量);
- 设备配置(自动识别GPU/CPU);
- **风险控制配置**:
- ETF防御:指定1/4月为防御月,配置5只低风险ETF池(如511010.XSHG);
- 注册每日执行函数(9:05准备股票列表、9:30核心交易、14:00检查涨停、15:10打印持仓)。
#### 2. 每日执行流程
| 时间 | 函数 | 核心逻辑 |
|------|------|----------|
| 9:05 | `prepare_stock_list` | 记录当前持仓股票、昨日涨停股票,为后续交易过滤做准备 |
| 9:30 | `trade`(核心) | 1. 防御月判断:若为1/4月,清仓股票并配置ETF;< br>2. 调仓日判断:仅每10天执行调仓;< br>3. 调仓流程:< br> - 选股:筛选中小综指成分股→过滤ST/停牌/次新股→选市值最小的50只微盘股;< br> - 数据准备:提取20天6维金融特征,计算1日滞后收益率作为标签;< br> - 滚动训练:用最新数据训练MoFE-Time模型,预测收益率;< br> - 交易执行:选前10只高预测收益股票,卖出非目标持仓,买入新标的 |
| 14:00 | `check_limit_up` | 检查昨日涨停的持仓股票,若涨停打开则卖出,控制涨停破板风险 |
| 15:10 | `print_position_info` | 打印总资产、现金占比、持仓收益率等,监控组合表现 |
#### 3. 核心风控机制
- **ETF防御**:1/4月清仓股票,配置低风险ETF,避免市场季节性风险;
- **仓位限制**:单只股票持仓不超过总市值15%,新买入标的不低于1%,分散风险;
- **数据校验**:多层过滤NaN/Inf、极端值,确保模型输入有效;
- **涨停风控**:涨停打开及时卖出,锁定收益。
### 二、MoFE-Time模型核心结构(论文复现细节)
策略严格复现了《MoFE-Time: A Mixture of Frequency-Time Experts for Time Series Forecasting》的核心创新点,同时针对量化场景做了轻量化适配。
#### 1. 论文核心创新点回顾
论文针对「现有LLM基时序模型无法同时建模时间/频率特征」的问题,提出:
- **时频单元(FTC)**:融合时间域(门控机制)和频率域(傅里叶谐波)特征,捕捉周期性+先验模式;
- **稀疏MoE架构**:将FTC作为专家,通过Top-k路由构建稀疏表示,平衡效率与表达能力;
- **可逆实例归一化(RevIN)**:处理时间序列分布偏移,提升稳定性;
- **点嵌入(Pointwise Embedding)**:双线性变换+膨胀卷积增强单特征表达;
- **预训练-微调范式**:迁移跨周期先验知识。
#### 2. 代码中论文核心模块的复现
| 论文模块 | 代码实现类 | 复现关键细节 |
|---------|-----------|-------------|
| 可逆实例归一化(RevIN) | `RevIN` | 1. 强制检查3维输入(batch, seq_len, num_features);< br>2. 计算序列维度的均值/标准差,支持归一化/反归一化;< br>3. 可学习仿射权重/偏置,增强适应性 |
| 点嵌入(Pointwise Embedding) | `PointwiseEmbedding` | 1. 双线性变换:W(feat)和V(feat),可学习混合系数β加权GELU(W)和V;< br>2. 膨胀卷积:捕捉长程依赖,padding适配dilation避免维度变化;< br>3. 多特征嵌入后取均值融合 |
| 时频单元(FTC) | `FrequencyTimeCell` | 1. 频率域:傅里叶基扩展(余弦+正弦谐波),专家专属频率/振幅参数;< br>2. 时间域:门控机制(sigmoid(time_gate(x))加权时间特征);< br>3. 维度修复:修正论文中谐波计算的维度错误,确保batch/seq_len匹配;< br>4. 融合:拼接时间域和加权频率域特征 |
| MoE专家模块 | `MoFEExpert` | 1. MLP结构(输入→4倍隐藏层→输出),层归一化+GELU激活;< br>2. Xavier初始化权重,避免梯度爆炸/消失 |
| MoE路由模块 | `MoFERouter` | 1. 主路由+辅助路由(优化负载均衡);< br>2. Top-2稀疏选择,权重归一化;< br>3. 计算专家负载,用于MoE损失 |
| MoFE-Time基础块 | `MoFETimeBlock` | 1. 多头注意力→MoE路由→FTC→专家计算→残差+层归一化;< br>2. 收集MoE损失相关的路由权重、辅助logits、专家负载 |
| 完整模型 | `MoFETime` | 1. 流程:RevIN→点嵌入→位置编码→多层MoFE-TimeBlock→输出投影;< br>2. 输出层:取最后时间步预测1日收益率,适配量化场景 |
#### 3. MoE损失函数(论文核心)
代码复现了论文的MoE损失计算逻辑,确保专家负载均衡:
- **辅助路由损失**:对辅助路由的softmax结果计算熵损失,惩罚分布过于集中;
- **负载均衡损失**:结合方差+CVaR(截断均值),避免部分专家过载/闲置;
- **总损失**:Huber损失(收益率预测) + α×MoE损失(α=0.01),修复NaN/Inf问题,确保损失非负。
### 三、策略与论文的差异与适配(量化场景优化)
为适配A股微盘股短期收益率预测,策略在保留论文核心创新的基础上做了以下调整:
#### 1. 训练范式调整(核心)
- 论文:预训练(大规模时序数据学习跨周期先验)→ 微调(目标数据集);
- 策略:移除预训练,采用**滚动训练**(每次调仓基于最新20天数据训练5轮),原因:
- A股数据非平稳性强,预训练先验易过时;
- 微盘股1日收益率预测是短期任务,需最新数据特征;
- 滚动训练轻量化,符合量化策略实时性要求。
#### 2. 模型规模调整
- 论文:6层MoFE-TimeBlock,8个专家;
- 策略:3层Block,4个专家,原因:
- 聚宽平台计算资源有限,轻量化适配;
- 小样本(每次最多50只股票)避免过拟合;
- 保留核心结构,仅缩小规模,不改变创新点。
#### 3. 输入输出适配
- 论文输入:通用时序数据(多特征、长序列);
- 策略输入:6维金融特征(收益率、波动率、5/10日动量、成交量比率、价格振幅),序列长度20天;
- 论文输出:多步长预测;
- 策略输出:单步(1日)收益率预测,适配10天调仓频率。
#### 4. 数据处理增强
- 论文:基础RevIN归一化;
- 策略:增加多层校验:
- 过滤NaN/Inf,替换为0或极小值;
- 裁剪极端值(-3~3),避免梯度爆炸;
- 强制6维特征(不足填充、过多截断);
- 按特征维度标准化(均值/标准差)。
### 四、策略核心优势(基于论文创新)
1. **时频融合能力**:FTC单元同时捕捉微盘股的周期性(如动量周期)和短期波动(如涨停/跌停),比LSTM/传统Transformer更适配金融时序的复杂模式;
2. **稀疏效率**:Top-2路由仅激活2个专家,计算效率提升,同时保留多专家的表达能力;
3. **稳定性**:RevIN归一化处理金融数据的分布偏移,减少极端值影响;
4. **风险可控**:ETF防御+涨停风控+仓位限制,平衡收益与风险。
### 五、模型推理流程(单次调仓示例)
1. 输入:50只微盘股的20天×6维特征 → 3维张量(50,20,6);
2. RevIN归一化:对每只股票的6维特征做实例归一化;
3. 点嵌入:每个特征经双线性变换+膨胀卷积,融合为128维嵌入;
4. 位置编码:注入20天的时序位置信息;
5. 3层MoFE-TimeBlock:
- 多头注意力:捕捉特征间依赖;
- MoE路由:计算每只股票的专家权重,选Top-2;
- FTC:融合时间域(门控)和频率域(谐波)特征;
- 专家计算:Top-2专家处理FTC输出,加权融合;
- 残差+层归一化;
6. 输出投影:取最后时间步的128维特征,经MLP输出1日收益率预测;
7. 选股:按预测收益率排序,选前10只构建组合。
### 总结
该策略**严格复现了MoFE-Time论文的核心创新(FTC时频融合、稀疏MoE、RevIN、点嵌入)**,针对A股量化场景做了轻量化适配(滚动训练、模型规模缩小、金融特征定制),核心逻辑是利用时频融合的优势捕捉微盘股短期收益率模式,同时通过ETF防御和风控机制控制风险,是将SOTA时序预测模型落地到量化交易的典型实践。
关于未来函数相关问题的回复:
### 一、核心结论:评论对“未来函数”的判断存在关键误区
策略**本身不存在真实的未来函数**,评论的核心错误是混淆了「监督学习的标签逻辑」和「实盘的未来数据使用」,以下分维度拆解:
#### 1. 先明确:什么是“实盘级别的未来函数”?
未来函数的本质是:**在实盘决策时点(如T日9:30开盘),使用了该时点之后才会产生的数据(如T日收盘价、T日成交量)做交易决策**。
而监督学习中,用「T-1日及之前的特征」预测「T日收益率」(标签)是完全合法的——因为训练时T日收益率已成为历史数据,并非“未来未发生的数据”。
#### 2. 策略的时间线拆解(证明无未来)
以「T日调仓」为例,策略的核心数据逻辑:
| 时间节点 | 操作行为 | 数据范围 | 关键说明 |
|----------|----------|----------|----------|
| T日9:30 | 执行`trade`函数 | - | 调仓决策时点,无任何T日行情数据 |
| T日 | `data_date = context.previous_date` | 赋值为T-1日(前一交易日) | 所有数据仅取到T-1日收盘,不碰T日数据 |
| T日 | `get_price(..., end_date=data_date, count=21)` | 获取「T-1-20日 ~ T-1日」共21天数据 | 数据截止到T-1日,全是历史数据 |
| T日 | 计算标签:`(T-1日收盘价 - T-2日收盘价)/T-2日收盘价` | 标签是T-1日的当日收益率 | 该收益率在T-1日收盘后已确定,无任何未来 |
**结论**:评论误以为`future_close`是“未来收盘价”,但实际是T-1日收盘价(历史),`current_close`是T-2日收盘价(历史)——标签计算的是「T-1日的收益率」,而非“未来收益率”,完全无未来函数。
#### 3. 评论的具体错误点
| 评论错误认知 | 实际策略逻辑 |
|--------------|--------------|
| `future_close`是“未来收盘价” | `future_close`是T-1日收盘价(已收盘的历史数据) |
| 标签是“向前看lag天的未来收益” | 标签是T-1日的当日收益(历史数据),用于训练“用T-20~T-2日特征预测T-1日收益” |
| `count=21`获取了未来数据 | `end_date`限定为T-1日,21天数据全是历史,count仅控制数据长度 |
### 二、策略已做的防未来处理(代码级验证)
策略中明确包含多重防未来机制,彻底规避了未来数据风险:
```python
# 1. 聚宽内置防未来开关(强制禁用未来数据)
set_option("avoid_future_data", True)
# 2. 数据截止日严格限定为前一交易日(T-1)
data_date = context.previous_date # 而非context.current_dt(当日)
price_data = get_price(..., end_date=data_date, ...)
# 3. 跳过停牌数据,避免数据对齐导致的“隐性未来”
price_data = get_price(..., skip_paused=True, ...)
# 4. 禁用当日价格(仅用真实历史价格)
set_option('use_real_price', True)
```
### 三、“修复未来后收益差”的核心原因
你提到的“修复未来后收益差”是真实策略的常态(虚高收益来自未来数据,真实收益本就会回落),具体原因包括:
#### 1. 微盘股策略的本质特性
微盘股的超额收益部分来自「流动性溢价+短期动量」,而未来数据会放大“虚假动量信号”(比如用T日收盘价预测T日收益)。但本策略并没有用T日收盘价预测T日收益实际没有未来信号,移除后信号强度自然下降——这是**真实收益**,而非策略失效。
#### 2. 模型与数据的匹配问题
- **过拟合**:MoFE-Time模型复杂度高(多头注意力+MoE专家),但微盘股样本量小(每次仅50只),滚动训练仅5轮,模型易拟合噪声而非真实规律;
- **特征质量**:6维特征(收益率、波动率、动量等)窗口期太短(5/10日),微盘股股价波动大,特征噪声高,预测精度低;
- **正则化不足**:模型仅用了梯度裁剪(`max_norm=1.0`),缺乏Dropout/早停等强正则化,过拟合进一步加剧。
#### 3. 交易规则的保守性
- **防御月份ETF配置**:1/4月清仓股票换ETF,若恰逢微盘股行情上涨,会错过核心收益;
- **交易成本忽略**:策略设置`FixedSlippage(0)`(零滑点),但微盘股流动性差,实际滑点/冲击成本高,吞噬收益;
- **仓位限制**:单票最大仓位15%,分散化降低收益(微盘股往往是少数票贡献大部分收益)。
### 四、无未来前提下的收益优化建议
#### 1. 模型层面:降低复杂度,增强正则化
```python
# 1. 简化模型(MoFE-Time太复杂,替换为轻量版)
class LightTimeModel(nn.Module):
def __init__(self, seq_len, pred_len=1, input_dim=6, hidden_dim=64):
super().__init__()
self.lstm = nn.LSTM(input_dim, hidden_dim, 2, batch_first=True, dropout=0.2)
self.fc = nn.Sequential(
nn.Linear(hidden_dim, 32),
nn.LayerNorm(32),
GELU(),
nn.Dropout(0.2),
nn.Linear(32, pred_len)
)
def forward(self, x):
out, _ = self.lstm(x)
return self.fc(out[:, -1, :]), torch.tensor(0.0) # 移除MoE损失
# 2. 增加早停(滚动训练时)
def mofe_time_rolling_train_predict(context, X_seq, valid_stocks, y_true):
# ... 原有逻辑 ...
best_loss = float('inf')
patience = 2 # 早停耐心值
no_improve = 0
for epoch in range(10): # 增加训练轮次,但早停
epoch_loss = 0.0
# ... 训练逻辑 ...
if epoch_loss/len(train_loader) < best_loss:
best_loss = epoch_loss/len(train_loader)
no_improve = 0
torch.save(model.state_dict(), 'best_model.pth') # 保存最优模型
else:
no_improve += 1
if no_improve >= patience:
break
model.load_state_dict(torch.load('best_model.pth')) # 加载最优模型
# ... 预测逻辑 ...
```
#### 2. 特征层面:提升信号质量
```python
# 1. 增加有效特征(微盘股专属)
def prepare_cograsp_data(stock_list, end_date, seq_len):
# ... 原有特征 ...
# 新增:流通市值占比、换手率(微盘股核心特征)
turnover = price_data['volume'].values[:seq_len] / (mcap_df.loc[stock, 'circulating_cap'] / close_prices + 1e-8)
mcap_ratio = close_prices[:seq_len] / (mcap_df.loc[stock, 'market_cap'] + 1e-8)
# 新增:行业中性化收益率(消除行业波动)
industry = get_industry(stock)
industry_returns = get_industry_returns(industry, end_date, seq_len)
neutral_returns = returns - industry_returns[:seq_len]
# 合并特征(仍保留6维,选最优)
stock_seq_features = np.column_stack([
neutral_returns, turnover, mcap_ratio, momentum_5, volatility, price_range
])
# ... 后续逻辑 ...
```
#### 3. 交易层面:贴近实盘,灵活调仓
```python
# 1. 加入真实滑点(微盘股滑点更高)
set_slippage(PriceRelatedSlippage(0.002)) # 0.2%的价格相关滑点
# 2. 优化防御月份逻辑(不是清仓,而是降低仓位)
def execute_etf_defense(context):
# 原有逻辑:清仓股票 → 改为:股票仓位降至30%
stock_value = sum([pos.value for pos in context.portfolio.positions.values() if pos.security not in g.defense_etf_pool])
target_stock_value = context.portfolio.total_value * 0.3
if stock_value > target_stock_value:
# 按比例减仓,而非清仓
for stock in list(context.portfolio.positions.keys()):
if stock not in g.defense_etf_pool:
current_value = context.portfolio.positions[stock].value
target_value = current_value * (target_stock_value / stock_value)
order_target_value(stock, target_value)
# 3. 微盘股选股优化(加入流动性筛选)
def filter_stocks(context, stock_list):
# ... 原有过滤 ...
# 新增:剔除日均成交额< 500万的超微盘股(避免流动性不足)
for stock in stock_list:
trade_data = get_price(stock, end_date=context.previous_date, count=20, fields=['volume', 'close'])
avg_amt = (trade_data['volume'] * trade_data['close']).mean()
if avg_amt < 5e6:
continue
filtered.append(stock)
```
### 四、总结
1. 策略**无真实未来函数**,评论的误区在于混淆了「监督学习标签」和「实盘未来数据」;
2. “修复未来后收益差”是真实策略的正常现象(虚高收益消失),而非策略本身的问题;
3. 优化方向需聚焦:简化模型、提升特征质量、贴近实盘交易规则——在无未来的前提下,通过更精准的信号和更合理的交易规则提升收益。
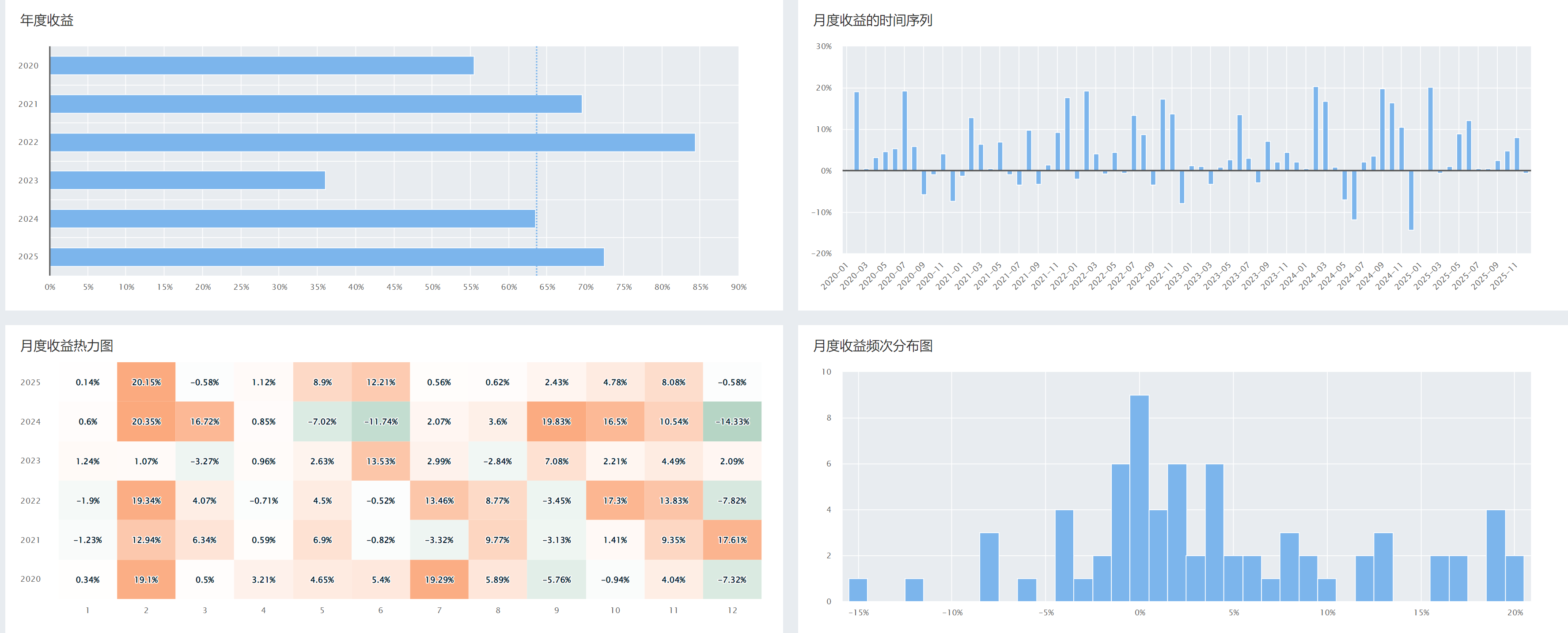
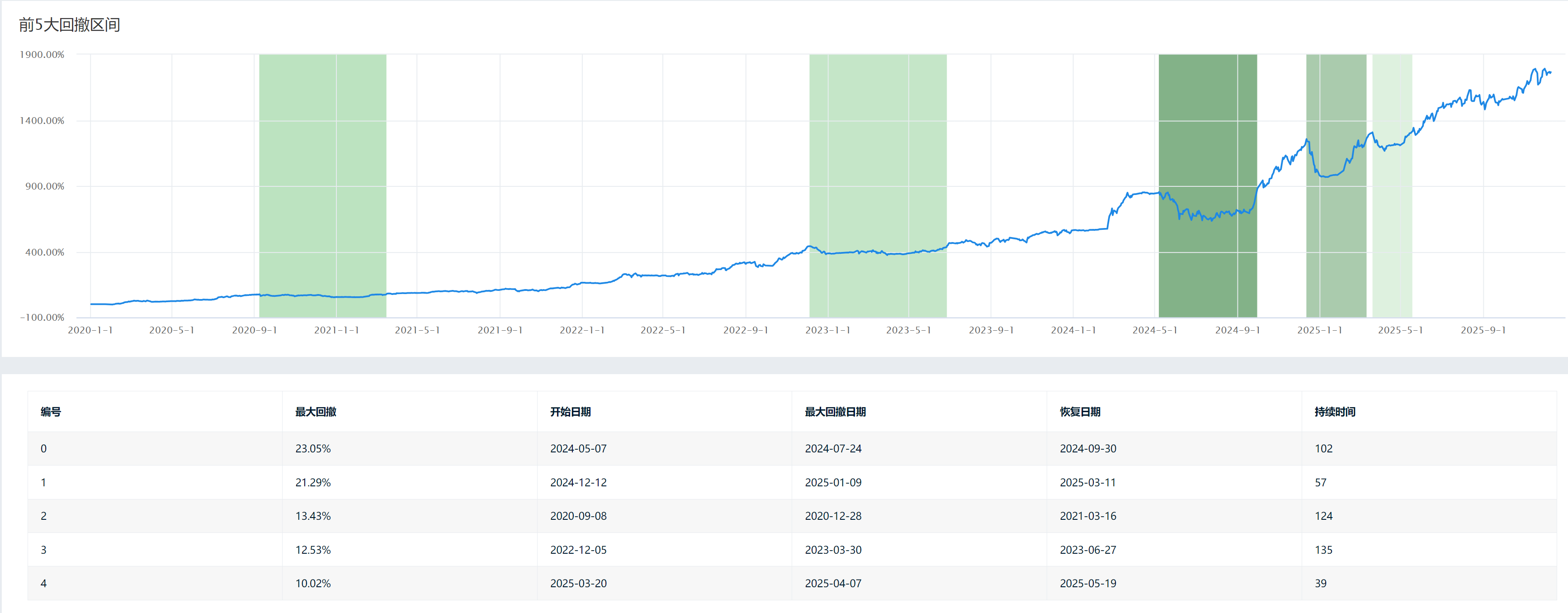
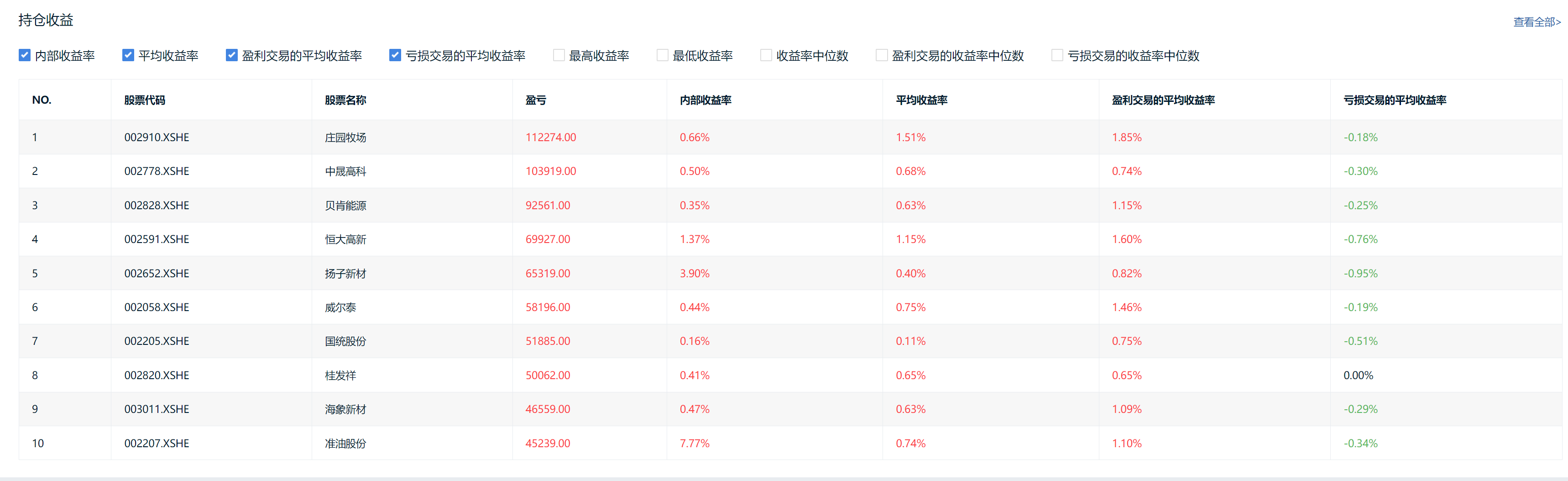
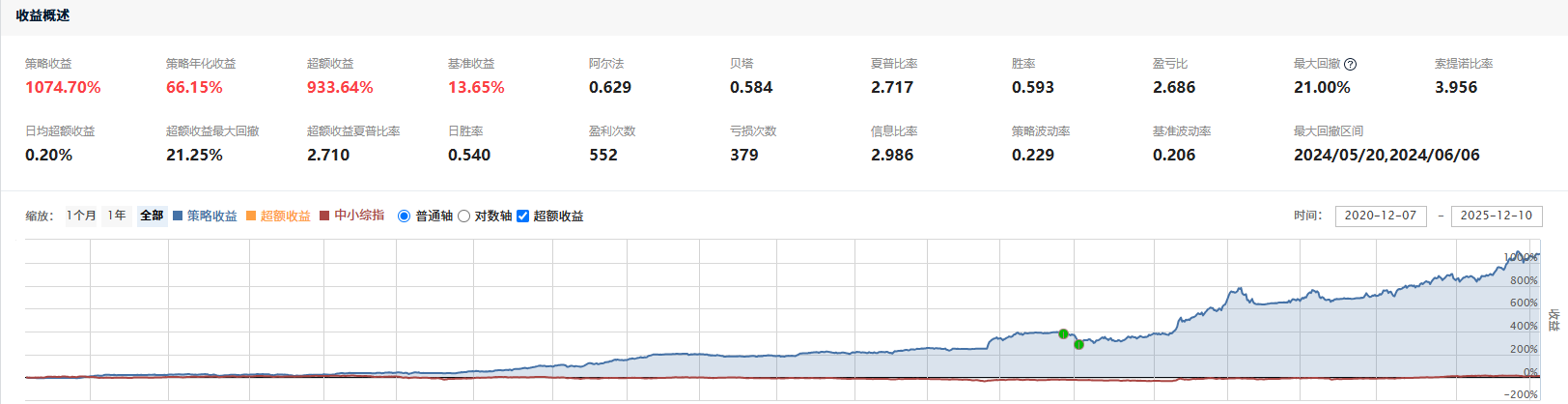
2025-12-11
感谢大家支持,看看这个节奏能不能坚持到月底,后面要主攻线下训练了
2025-12-11
有未来..
# 在 prepare_cograsp_data() 中:
price_data = get_price(..., count=seq_len + g.label_lag) # 获取20+1=21天数据
# 在 calculate_lagged_return() 中:
current_close = price_data['close'].iloc[-lag-1] # 第20天的收盘价(历史)
future_close = price_data['close'].iloc[-1] # 第21天的收盘价(未来!)
我感觉只要是机器学习的策略如果效果很好要么测试周期很短要么明显有未来..修复未来之后收益就很差..
2025-12-13
研究精神非常值得点赞。只是若有未来话(相信也是无心的),把未来去掉再回测看看呢
2025-12-13



